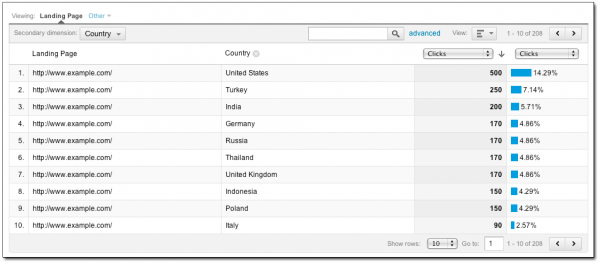
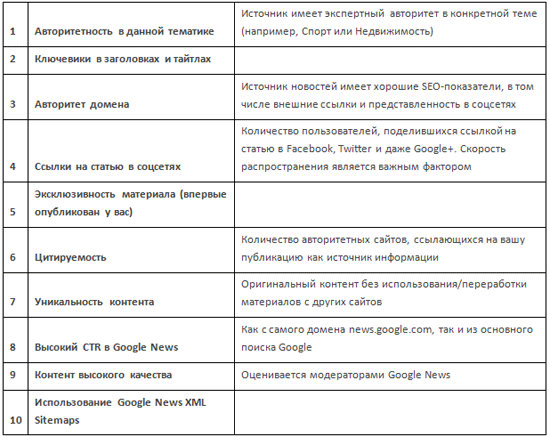
Как конкуренты могут ликвидировать вас в выдачеПримечание: не используйте эти методы.
Если вы не можете выбить сайт конкурента из выдачи, уничтожьте его. Если вы не можете его уничтожить, то займитесь его хостингом.
Ссылки – входящие – старыеНайдите хорошие ссылки ваших конкурентов и попросите владельцев площадок перенаправить их на ваш сайт. Если это не сработает, отправьте им жалобу. Напишите им: «Вы ссылаетесь на плохой сайт и если вы не уберёте ссылку, то понесёте юридическую ответственность». Вы удивитесь, как много сайтов снимут ссылки.
Если это не помогает, попробуйте пригрозить санкциями в отношении торговой марки. Если и это не помогает, попробуйте подделать письмо от Google с предупреждением. Это довольно интересные методы, потому что таким образом вы можете не только «украсть» ссылки конкурентов, но и сделать это так, чтобы не получить никаких санкций со стороны поисковых систем.
Ссылки – входящие – новыеТеперь, когда вы избавились от старых хороших ссылок конкурентов, самое время на их место получить новые. Поищите ссылочные фермы и сети, забаненные и взломанные сайты, фейковые профили со спамом, заспамленные аккаунты в блогах, чатах, Твиттере, подойдут даже платные ссылки, о которых непременно нужно будет сообщить в Google.
На самом деле довольно много сообщений о спаме поступает в Google именно от чёрных сеошников.
Если вы хотите, чтобы Google наверняка посчитал эти ссылки, как спам, постарайтесь установить на эти спамные сайты Adsense.
Теперь с этих заспамленных площадок устанавливаем ссылки на конкурента.
Примечание: опять же, это то, что делают ваши враги, а не то, что должны делать вы сами.
XSS, взлом, внедрение виджетов и кодов, ссылки из комментариев и других областей. Используйте виджеты третьих лиц аккуратно: смотрите, чтобы они не понаставили ссылок с ваших собственных сайтов.
Вы будете удивлены, когда узнаете, как много опытных сеошников не обращают внимания на out.php или go/to/url типы ссылок, которыми можно манипулировать.
Манипуляция контентомСоздавайте на сайте конкурента дублированный контент и/или помогайте ему индексироваться (хорошо, что мы только что узнали, как от этого защититься).
Модерируется ли форум конкурента? Потратьте немного времени и опубликуйте там несколько «познавательных» статей. То же самое касается комментариев, отзывов и т.д. Если у вас на сайте есть подобные разделы, то вы их
обязаны модерировать. Так же поищите 1-пиксельные шрифты, DHTML-дыры и клоакинг, если позволяете пользователям размещать HTML и скрипты.
Пройдёмся по сайтуМожно ли получить доступ к файлу robots.txt конкурента из-за неправильных настроек сервера? Есть ли возможность добавить такие теги, как noindex и nofollow? Так же не забывайте про XSS.
Помните: чёрные сеошники могут использовать вашу открытую информацию из WHOIS для отправки спама со своих доменов.
Можете ли вы получить доступ к панели веб-мастера конкурента или к его аккаунтам в социальных сетях? Достаточно ли квалифицированные сотрудники работают в вашей компании, чтобы не разглашать подобные сведения? Несколько месяцев назад эти данные можно было с лёгкостью получить, используя всего несколько строк HTML-кода, но сейчас уязвимость уже прикрыли.
Внешние факторыDMCA и TM по-прежнему являются неплохими инструментами.
Вы владеете доменами *название компании* во всех зонах? Если нет, то с них могут спамить ваши конкуренты, используя ваши данные WHOIS.
Ещё одним огромным источником дублированного контента могут быть прокси сайты.
Недавно Google ввёл новый механизм – «Свежесть», используйте и его. Направляйте большие объёмы контента через RSS и скармливайте свой поток различным агрегаторам этих лент. Так вы наверняка обойдёте статичные сайты.
Если вас до сих пор нет на картах Google, то кто-нибудь может рассказать ему, что ваша компания находится где-нибудь в Африке.
Чёрное PPCЕсли у вас есть ежедневный бюджет на контекстную рекламу, то некто может его с лёгкостью потратить, используя бота ранним утром.
Так же они могут использовать ваш код контекстной рекламы или ID рекламодателя на каких-нибудь сомнительных сайтах, чтобы создать для вас лишние проблемы вместо конверсии.
Кроме того, при помощи некоторых инструментов можно перенаправлять посетителей с сайтов на сайт конкурента без их на то согласия.
Критика- Можно нанять людей, которые расскажут всем о покупке ссылок конкурентами.
- Можно нанять людей, которые расскажут, как сайт вашего конкурента обманывает поисковые системы и это сходит ему с рук. И вы к этому не будете иметь никакого отношения. Всё за вас сделают тысячи ботов из Индии или Китая.
- Можно так же нанять людей, которые будут жаловаться на распространение вирусов.
АналитикаОтправляя ложные запросы на сайт конкурента можно серьёзно осложнить работу их аналитическому отделу. Не забываем здесь и о ботнетах.
ВзломКогда ничего не действует, они могут просто взломать.
- 302 взлом всё ещё работает
- Клоакинг и 301 редирект
- Клоакинг и редирект через скрипты – а потом сообщаем об этом в Google.
- Порча DNS.
- Использование поддельных кредитных карточек может уничтожить ваш торговый аккаунт.
- Кросс-доменные вызовы.
Человеческий факторПодкупите сеошника вашего конкурента. Или распространите от его имени резюме, может его наймёт кто-то ещё. Или внедрите своего человека в фирму конкурента.
Отказ в обслуживании (DDOS)Однажды я подвергся подобной атаке. Но к счастью ДДОС был на уровне домена, а не IP, поэтому я с лёгкостью перенаправил его на конкурента. ДДОС может навредить всем вашим сайтам на сервере. Так же однажды я потерял сайт, когда сотрудники ФБР прикрыли весь сервер из-за другого сайта. Тоже неплохая тактика!


")